
This is post 3 of 9 in our Little's Law series.

Having explained in an earlier post in the series that Little's Law (LL) comes in at least two flavors, it's time for another thought experiment. For this test, I'm going to ask you to fabricate some flow data over an arbitrarily long period of time.
In order to keep the experiment as simple as possible, the requirements for our fabricated data are going to be quite specific, so please allow me to list them here:
Your flow data must start with zero WIP. Trust me, the experiment works equally well if you start with non-zero WIP, but in order to eliminate the possibility of certain edge cases occurring, let's all start with zero WIP.
For the whole period of time under consideration, the arrival rate of your data must be constant. For example, if the arrival rate for the first day is two items, then the arrival rate for the second day must be two items, as well as two items for the third day, etc., for the whole span of your dataset.
Likewise, the departure rate (Throughput) for your data must be constant for the whole time period under consideration AND must be less than your arrival rate. This should make sense. If we start with zero WIP, it would be impossible to have a constant departure rate greater than your arrival rate--otherwise, your WIP would turn negative (which, of course, is impossible). So, for example, if the departure rate for the first day of your dataset is one item, then the departure rate for the second day must also be one item, as well as one item for the third day, and so on for the whole span of your dataset.
Items must move through your process and complete in strict first-in-first-out (FIFO) order. Again, this need not be strictly necessary, but it makes conjuring your dataset easier.
The length of time for your dataset is completely up to you, but make it realistic, say, the length of one or two Sprints, the length of one of your releases, or the like.
Got it? (I'm hoping the reasons for the specificity of these requirements will become clear shortly.)
You'll recall from this earlier post that to calculate flow metrics, all you need to have is the start date and end date of each item that moves through your system. Thus, the following (Figure 1) might be some example data that we might use for this experiment:
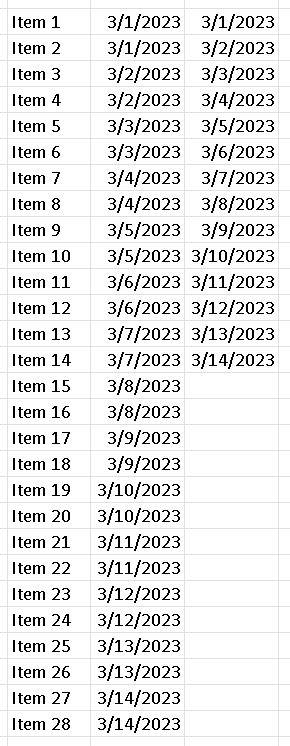
Figure 1 - Sample data
Please note (and please forgive) the use of American-style dates above. "3/1/2023" is 1 March 2023, not 3 January 2023.
You'll further recall from that earlier post that it is rather straightforward to calculate flow metrics from our item date data:
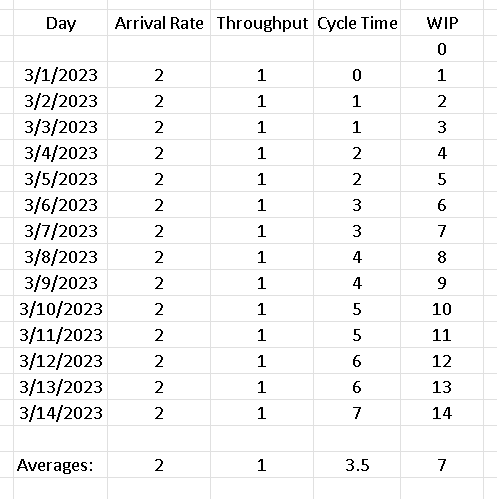
Figure 2 - Flow Metrics Calculated From Sample Data
Figure 2 above shows the arrival rate, Throughput, Cycle Time, and WIP for every single day of the time period under consideration (again, using American-style dates). The astute reader will notice the mathematically correct nuance of how the averages were calculated, which I hope to address in a future post. Now that we have all of our flow metrics derived, we can do some LL calculations for comparisons.
We left off last time by pointing out that we have two versions of LL to deal with. The first is
L = λ * W
Where L is the average queue length (WIP), λ is the average arrival rate, and W is the average wait time (Cycle Time).
Plugging in numbers from Figure 2, we have L = 7, λ = 2, and W = 3.5, or
7 = 2 * 3.5
which, of course, is correct.
However, in the case of the second form of LL:
WIP = TH * CT
where WIP is the average work in progress, TH is the average Throughput, and CT is the average Cycle Time; when we plug in numbers, we get WIP = 7, TH = 1, and CT = 3.5, or
7 = 1 * 3.5
which, of course, is NOT correct.
So how is it that we can have two forms of a "law" where one is correct, and the other is incorrect?
Any mathematical theorem you can think of comes with a set of assumptions that must be in place in order for the theorem to be valid.
I can guarantee you that the problem isn't with LL. The problem is with us and our understanding of LL. Let me explain.
Any mathematical theorem you can think of comes with a set of assumptions that must be in place in order for the theorem to be valid. Violate any one (or more) of the assumptions at any time (or times), and the results you get in practice will not match the theory.
For example, the fundamental theorem of calculus requires that you are dealing with (amongst other things) real-valued, continuous functions. Unless you are a mathematics geek, you may not know what any of that means but violate any one of those assumptions, and most of what you learned in your Calc 101 class becomes meaningless.
Because it is an equation, most people want to rush to plug numbers in [Little's Law] to see what comes out the other side--without really understanding what they are doing.
Little's Law is no different. It's worse, even. Because it is an equation, most people want to rush to plug numbers in to see what comes out the other side--without really understanding what they are doing. The prevailing Lean-Agile literature perpetuates this myth by suggesting you can do just that. (I'm loathe to give any examples here lest I become part of the problem, but just search the interwebs on your own for Little's Law in Agile, and you will see what I mean). What's worse is that many of those "sources" will tell you that you can use Little's Law as a predictor for what will happen if you take specific action. In other words, Little's Law will tell you exactly what your Cycle Time will be if you cut your WIP in half (spoiler alert: it won't).
Another way of saying the above is that most people see L = λW, and they want to treat it like E = mc^2^ or F = ma. That is to say, they want to plug two of the three parameters into the equations to see if they can predict what the third parameter will be in some future state of the system. So if our current WIP is 12 and our current Throughput is 2, then all we need to do to get our future Cycle Time down to 3 is to cut our WIP in half while keeping our Throughput at 2 at the same time. I'm sorry to say it doesn't work like that. At all.
The work to dispel these myths will start with the next post in this series. It will be a bit of a slog, and the minutia might seem tedious, but my hope is that if you stick with it, you will gain a much deeper appreciation for the law. That detailed discussion of what assumptions need to be in place for LL to be valid and how those assumptions apply to your own process data begins next.
Explore all entries in this series
The Two Faces of Little's Law (this article)
The Most Important Metric of Little's Law Isn't In the Equation
About Daniel Vacanti, Guest Writer

Daniel Vacanti is the author of the highly-praised books "When will it be done?" and "Actionable Agile Metrics for Predictability" and the original mind behind the ActionableAgile™️ Analytics Tool. Recently, he co-founded ProKanban.org, an inclusive community where everyone can learn about Professional Kanban, and he co-authored their Kanban Guide.
When he is not playing tennis in the Florida sunshine or whisky tasting in Scotland, Daniel can be found speaking on the international conference circuit, teaching classes, and creating amazing content for people like us.
