
Before proceeding, it would be worth reviewing Julia's excellent posts on the four basic metrics of Flow:
The definitions are great but are, unfortunately, meaningless unless we know what data we need to capture to calculate them. In terms of data collection, this is where our harping on you to define started and finished points will finally pay off. Take a timestamp when a work item crosses your started point and take another timestamp when that same work item crosses your finished point. Do that for every work item that flows through your process as shown below (forgive the American-style dates):
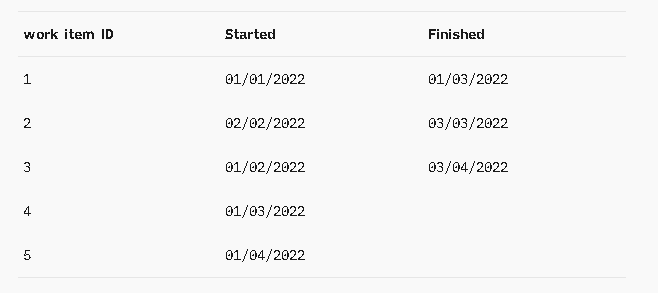
That's it. To calculate all the basic flow metrics, this is the only data you will need.
To calculate any or all of the basic metrics of flow, the only data you need is the timestamp for when an item started and the timestamp for when an item finished.
Even better, if you are using some type of work item tracking tool to help your team, then most likely your tool will already be collecting all of this data for you. The downside of using a tracking tool, though, is that you may not be able to rely on any out-of-the-box metrics calculations that it may give you. It is one of the great secrets of the universe as to why many Agile tools cannot calculate flow metrics properly, but, for the most part, they cannot.
Luckily for you, that's what this blog post is all about. To properly calculate each of the metrics from the data, do as follows:
WIP
WIP is the count of all work items that have a started timestamp but not a finished timestamp for a given time period. That last part is a bit difficult for people to grasp. Although technically, WIP is an instantaneous metric--that is, at any time you could count all of the work items in your process to calculate WIP--it is usually more helpful to talk about WIP over some time unit: days, weeks, Sprints, etc. Our strong recommendation--and this is going to be our strong recommendation for all of these metrics--is that you track WIP per day. Thus, if we would want to know what our WIP was for a given day, we would just count all the work items that had started but not finished by that date. For the above picture, our WIP on January 5th is 3 (work items 3, 4, and 5 have all started before January 5th but have not been finished by that day).
Cycle Time
Cycle Time equals the finished date minus the started date plus one (CT = FD - SD + 1).
If you are wondering where the “+ 1” comes from in the calculation, it is because we count every day in which the item is worked as part of the total. For example, when a work item starts and finishes on the same day, we would never say that it took zero time to complete. So we add one, effectively rounding the partial day up to a full day. What about items that don't start and finish on the same day? For example, let's say an item starts on January 1st and finishes on January 2nd. The above Cycle Time definition would give an answer of two days (2 – 1 + 1 = 2). We think this is a reasonable, realistic outcome. Again, from the customers' perspective, if we communicate a Cycle Time of one day, then they could have a realistic expectation that they will receive their item on the same day. If we tell them two days, they have a realistic expectation that they will receive their item on the next day, etc.
You might be concerned that the above Cycle Time calculation might be too biased toward measuring Cycle Time in terms of days. In reality, you can substitute whatever notion of "time" that is relevant for your context (that is why up until now, we have kept saying track a "timestamp" and not a "date"). Maybe weeks are more relevant for your specific situation. Or hours. Or even Sprints. [For Scrum, if you wanted to measure Cycle Time in terms of Sprints, then the calculation would just be Finished Sprint – Start Sprint + 1 (assuming work items cross Sprint boundaries in your context).] The point here is that this calculation is valid for all contexts. However, as with WIP, our very strong recommendation is to calculate Cycle Time in terms of days. The reasons are too numerous to get into here, so when starting out, calculate Cycle Time in terms of days and then experiment with other time units later should you feel you need them (our guess is you won't).
Work Item Age
Work Item Age equals the current date minus the started date plus one (Age = CD - SD + 1).
The "plus one" argument is the same as for Cycle Time above. Our apologies, but you will never have a work item that has an Age of zero days. Again, our strong recommendation is to track Age in days.
Throughput
Let's take a look at a different set of data to make our Throughput calculation example a bit clearer:
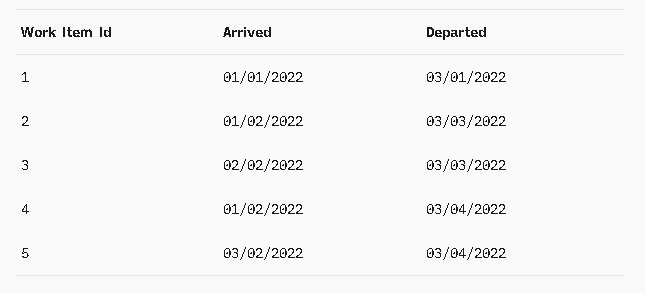
To calculate Throughput, begin by noting the earliest date that any item was completed, and the latest date that any item was completed. Then enumerate those dates. In our example, those dates in sequence are:
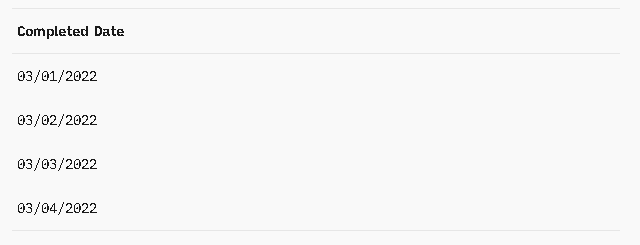
Now for each enumerated date, simply count the number of items that finished on that exact date. For our data, those counts look like this:

From Figure 2.4, we can see that we had a Throughput of 1 item on 03/01/2016, 0 items the next day, 2 items the third day, and 2 items the last day. Note the Throughput of zero on 03/02/2016 --nothing was finished that day.
As stated above, you can choose whatever time units you want to calculate Throughput. If you are using Scrum, your first inclination might be to calculate Throughput per Sprint: "we got 14 work items done in the last Sprint". Let us very strongly advise against that and advise very strongly that you measure Throughput in terms of days. Again, it would be a book in itself to explain why, but let us just offer two quick justifications: (1) using days will provide you much better flexibility and granularity when we start doing things like Monte Carlo simulation; and, (2) using consistent units across all of your metrics will save you a lot of headaches. So if you are tracking WIP, Cycle Time, and Age all in days, then you will make your life a whole lot simpler if you track Throughput in days too. For Scrum, you can easily derive Throughput per Sprint from this same data if that still matters to you.
Randomness
We've saved the most difficult part for last. You now know how to calculate the four basic metrics of flow at the individual work item level. Further, we now know that all of these calculations are deterministic. That is, if we start a work item on Monday and finish it a few days later on Thursday, then we know that the work item had a Cycle Time of *exactly* four days.
But what if someone asks us what our overall process Cycle Time is? What our overall process Throughput is? How do we answer those questions?
Our guess is you immediately see the problem here. If, say, we look at our team's Cycle Time for the past six weeks, we will see that we had work items finish in a wide range of times. Some in one day, some in five days, some in more than 14 days, etc. In short, there is no single deterministic answer to the question, "What is our process Cycle Time?". Stated slightly differently, your process Cycle Time is not a unique number, rather, it is a distribution of possible values. That's because your process Cycle Time is really what's known as a random variable. [By the way, we've only been talking about Cycle Time in this section for illustrative purposes, but each of the basic metrics of flow (WIP, Cycle Time, Age, Throughput) are random variables.]
What random variables are and why you should care is one of those topics that is way beyond the scope of this post. But what you do need to know is that your process is dominated by uncertainty and risk, which means all flow metrics that you track will reflect that uncertainty and risk. Further, that uncertainty and risk will show up as randomness in all of your Flow Metric calculations.
How variation impacts the interpretation of flow metrics and how it impacts any action that should be taken to improve your process will be the topic of a blog series coming later this year. For now, what you need to know is that the randomness in your process is what makes it stochastic. You don't necessarily need to understand what stochastic means, but you should understand that all stochastic processes behave according to certain "laws".
One such law you may have heard of before...
About Daniel Vacanti, Guest Writer

Daniel Vacanti is the author of the highly-praised books "When will it be done?" and "Actionable Agile Metrics for Predictability" and the original mind behind the ActionableAgile™️ Analytics Tool. Recently, he co-founded ProKanban.org, an inclusive community where everyone can learn about Professional Kanban, and he co-authored their Kanban Guide.
When he is not playing tennis in the Florida sunshine or whisky tasting in Scotland, Daniel can be found speaking on the international conference circuit, teaching classes, and creating amazing content for people like us.
